It’s almost impossible to avoid bugs when developing software, but there are ways to decrease the likelihood of them happening. GitLab includes tools that make software development easier by constantly checking the code and ensuring that everything goes smoothly fine. Here’s how to achieve a good workflow with GitLab.
Continuous Integration (CI) works by pushing code to an application hosted in a Git repository. In every push, the app runs a pipeline of scripts to build, test, and validate the code changes before merging them into the main branch. Continuous Deployment (CD) goes one step further than CI, by deploying the application to a production server on every push, to the default branch of the repository.
GitLab is built with its own powerful system of Continuous Integration and Continuous Deployment. In order to configure the CI/CD for a GitLab project, a configuration file called gitlab-ci.yml should be placed at the repository’s root. The file will be executed by the GitLab Runner, where the building and testing of the application will be made on every push to the repository.
The GitLab Runner is an open-source project that is used to run jobs and send the results back to GitLab. This service is included with GitLab and is used in conjunction with it to execute the pipeline script from the CI and CD.
Implementing CI and CD
To get started implementing CI/CD on your project, you will need to push it to GitLab and add the configuration file mentioned previously. The file will contain scripts grouped into jobs, and together they compose a pipeline. Here’s a simple example of how this file looks,
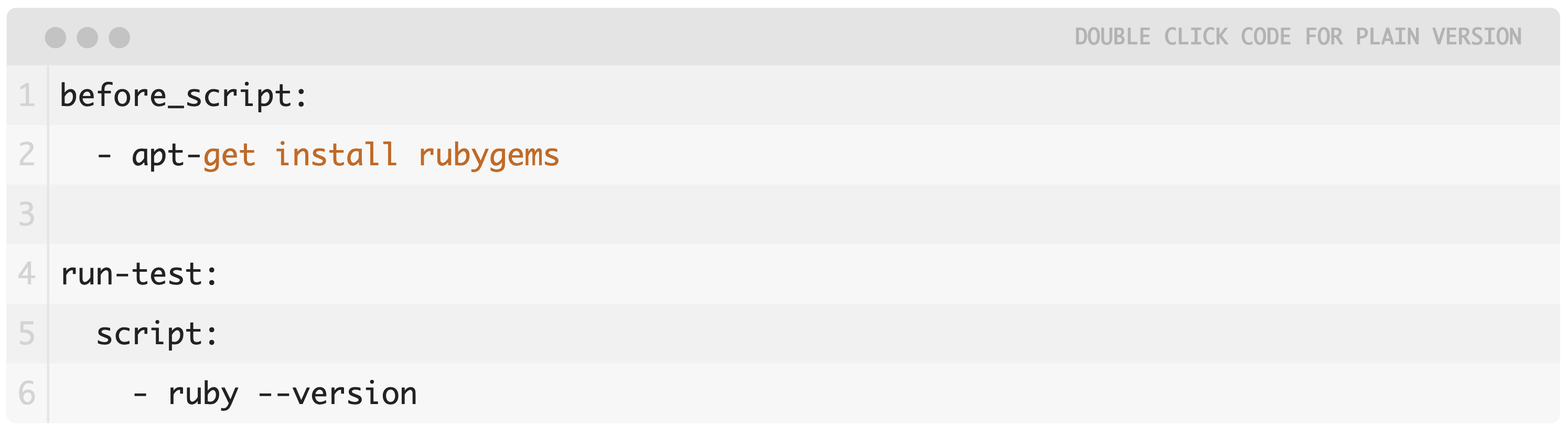
In this example, the before_script attribute will install the dependencies for the application before running anything. Then a job called run-tests will execute the script and it will show the Ruby version of the current system. Both of these compose a pipeline triggered at every push to any branch of the repository.
There are a lot of different attributes and scripts that you can run. The whole purpose of CI is to test everything before making any merge between branches and automate it.
Organizing Jobs with Stages
The purpose of a job is to run scripts and sometimes those scripts need to have an order of execution, that’s where the stages come in. To explain better how stages work, here is an example,

The stage is defined as per-job and relies on stages that are defined globally. This allows you to group jobs into different stages, and the jobs of the same stage are executed in parallel. The .pre stage is guaranteed to always be the first stage in a pipeline and .post is guaranteed to always be the last stage in a pipeline. In the last example, the jobs will be executed chronologically from job .pre to .post.
You can define the order of how things should be executed. If continuous integration or deployment goes wrong during the way, GitLab will notify you. You can fix those errors before doing any merge you may regret.
One big advantage of having the GitLab CI/CD is that it not only lets you run these scripts, but it also provides an interface showing what is happening during the execution of the scripts on the config file. Here is a screenshot of how the CI/CD tab looks when a push is made to the repository,
From the build to deploy, you can see all the logs of what is going on with your CI/CD. So if something fails, you will know exactly what went wrong. Only if you have good test coverage on your project, though.
Another great feature of GitLab CI/CD is that when implemented, on every push made it will show you if the tests on de CI passed, are running or failing.

Finally…
There are a ton of different attributes and scripts you can run. To get started with GitLab CI/CD, you need to know the .gitlab-ci.yml configuration file syntax and its attributes. For more information and documentation visit the Introduction to CI/CD with GitLab and GitLab CI/CD Pipeline Configuration Reference.
If you have any questions, please contact me at hbustillos@nearsoft.com.

