Despite the many advantages brought by Robust Random Cut Forests (RRCF), as described in the previous part, the base technique does not solve some problems related to anomaly detection directly.
The first challenge is regarding the time series nature of most anomaly detection problems: while a tree-based structure can identify single datapoints that are anomalous (and, in this case, do it in a robust, flexible way), a single datapoint isn’t enough to characterize an anomaly or not. For example, it’s impossible to know if someone making 10 calls of 30 seconds each over 15 minutes is anomalous – for a call center this might be the expected behavior, but for a seldom-used number it might not be. In other words, the same datapoint might be anomalous in one context but regular in another.
In order to solve this issue, we obtained promising results by adding a preprocessing step in which context is added to the datapoints. The main advantage of encoding the context together with datapoints is that, in this way, anomaly detectors can analyze behaviors rather than only events: if similar characteristics have been identified elsewhere, they will be treated in a similar way. Thanks to the robustness of RCFF, this means that the transition in behaviors will be perceived. Since that specific combination of context features is fairly unique in the dataset. Of course, completely new behaviors will also be identified, since they’re likely to violate known patterns.
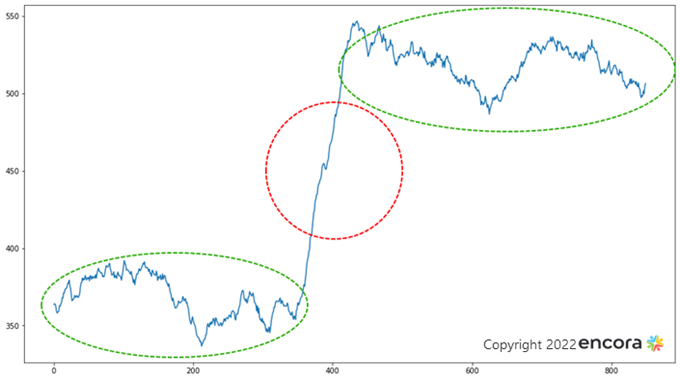
The transition between two relatively stable behaviors' is often anomalous
Finally, this approach also adds time-invariance to the analysis, since the same context can be perceived in different moments of time and mapped together as the same ‘known’ event (I.e., they will fall in the same branch of the tree and be separated by only their particular characteristics).
Improvements: Inference Optimization
Once data is preprocessed and its context is described, training can be resumed as usual – either in batch mode or iteratively since RRCF also supports streamed learning. However, while the algorithm is fairly optimized for tree building and evaluation; inference costs would be proportional to the cost of calculating the displacement of each new example on each tree, which is proportional to the tree size.
However, in very large datasets, in which historical or general behavior is more relevant than just the most recent events (for example, when there is a high throughput of events), constant relearning might bias the forest towards recent behaviors and slow down inference.
Thanks to the tree structure used in RRCF, it not only supports binary search but also further optimizes it by providing the bounding box information of each subtree. This information can be used, instead, to search a tree for the most similar leaf (or for the branch in which it would be forked out) in a much quicker fashion. This approximation can be used as long as the data is not randomly distributed over the dimensions (and, thanks to the algorithm that builds the trees in the first place, this would only be the case if all dimensions were randomly distributed, since it will give precedence to dimensions that improve data separation).
Improvements: Explainable Results
Once trees have been built and inference is running, it’s also important to provide explainability. Since this technique is based on trees, it is possible to understand the decisions that were taken to evaluate each data point on each tree. However, this information alone might not be enough to provide value to specialists, given the fact that multiple trees can exist in the forest with different nodes, structures and evaluations. This is also added to the fact that, even though the calculated displacement is robust to irrelevant dimensions, they will still be listed.
Additional valuable information for analysts is not only knowing why a certain event was classified as anomalous, but also compared to what it was considered to be anomalous. As explained before, real systems might present multiple distinct behaviors, and identifying the characteristics that place an event outside them is not enough to identify the problem if the expected characteristics are not easily known.
In order to provide both types of data, statistical measurements can be taken from all the nodes that enable a reduction in the number of items that need to be reviewed. More specifically, by using the pre-calculated bounding boxes (in all dimensions) that isolate leaves, it allows analysts to look at a single snapshot that contains the expected interval for such datapoint and in which dimensions it was beyond the bounding box’s thresholds, instead of at dozens (or hundreds) of trees and the numerous tree nodes.
This information is relevant for two reasons: it provides a clear explanation of why a certain datapoint was considered to be an outlier (due to the thresholds that were crossed), and also which kind of general behavior was being modelled by the system (given by the bounding box statistics). The first one is useful for the end users of the system, which can, then, take the best approach based on the type of anomaly/infraction. While the second one is useful for the maintenance and design of the training model itself. A bounding box that does not consider key elements means that important features are not being considered, while its general size and variance can be used to determine whether the trees are too generalist (and could be deepened) or too specific (and could be pruned).
Results and Conclusions
Despite the unsupervised nature of the anomaly detection problem, experiments with advanced behavior-based simulators have shown that RRCF can achieve remarkably high precision ratings of above 95%, with recalls between 50% and 75% of the generated anomalies. Even in problems that presented many possible behaviors with high noise rate (up to 50%) and anomalies that relied on multiple features at the same time. These experiments were developed to provide objective results and compare this technique against other detection methods currently employed by Encora’s partners.
Based on the experimental results and described characteristics, Robust Random Cut Forests are a reliable and efficient learning algorithm for anomaly detection that provides robust, unsupervised, multivariate learning with scalable and explainable results, and can be used in multiple applications that require detection over large groups of unlabeled data with multiple possible behaviors over time.
The main limitations of this technique are the necessity of pre-possessing steps, since the aggregation of data in order to contain contexts is essential to identify behaviors and their changes over time. A proper normalization of features is also important for feature selection even though finetuning is not strictly necessary due to how the displacement value is calculated, relative to the number of datapoints that are isolated.
Finally, the transparency and robustness of this technique make it particularly interesting during exploration phases. Since its analysis can be iterated and improved together with domain specialists without requiring previous knowledge or input from them. Due to its natural scaling, it’s also possible to apply the same technique as the project evolves into later stages without the need for reimplementation.
References:
- Robust Random Cut Forests. Sudipto Guha, Nina Mishra, Gourav Roy, Okke Schrijvers Proceedings of The 33rd International Conference on Machine Learning, PMLR 48:2712-2721, 2016.
- Forecasting at scale. Taylor SJ, Letham B. 2017. Forecasting at scale. PeerJ Preprints 5:e3190v2 https://doi.org/10.7287/peerj.preprints.3190v2
- Anomaly Detection: a Survey. Varun Chandola, Arindam Banerjee, and Vipin Kumar. 2009. Anomaly detection: A survey. ACM Comput. Surv. 41, 3, Article 15 (July 2009), 58 pages. https://doi.org/10.1145/1541880.1541882
Acknowledgement
This article was written by Ivan Caramello, Data Scientist and member of the Data Science & Engineering Tech Practices at Encora. Thanks to Daniel Franco, Alicia Tasselli, Caio Vinicius Dadauto , João Caleffi and Kathleen McCabe for reviews and insights.
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.

