Human emotions are complex and difficult to decode. However, recent advancements in artificial intelligence and deep learning, are enabling new leaps in sentiment analysis. Put simply, sentiment analysis is a machine decoding human emotions for a specific purpose.
Applications vary from mining opinions to gauging political inclinations to see how product reviews are affecting real-time sales. Social media companies actively use sentiment analysis to root out offensive and prejudiced content. It is a vital tool to derive “sense” from the data.
One of the most critical applications of natural language processing is the categorization of text documents.
While challenges still exist, newer cutting-edge techniques are emerging that finally seem to have a handle on getting sentiment analysis right ![]()
This post details some of these challenges and techniques.
Common challenges
Some of the common challenges NLP practitioners face with sentiment analysis include:
Identifying the presence of negation words: Humans themselves often find it difficult to gauge the meaning of negation words that have sentiments other than their explicit meaning. Language algorithms often have trouble understanding the connotation of phrases such as ‘not great,’ ‘not bad,’ which often have neutral to positive sentiment associated with them vs. ‘not good’ which mostly conveys a negative sentiment.
Multipolar ways of expressing thoughts: Often, when expressing opinions, humans are unsure of their liking or disliking. Analysis algorithms find it difficult to judge the polarity of such ideas when expressed as text. For e.g, in the statement given below the user is expressing multiple opinions about a person that are opposite to each other.
“He is either an extremely nice but stupid guy or one of the most sickest liars”
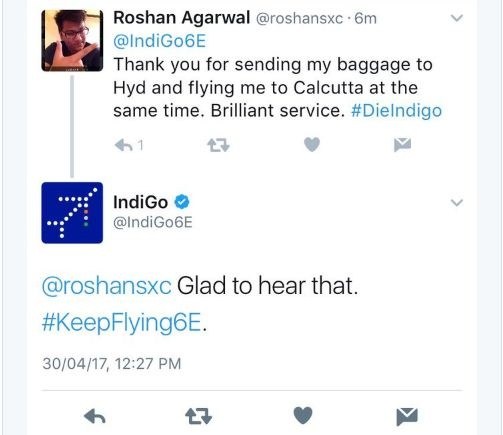
Sarcasm: Humans often use sarcasm to express frustration or disappointment. This is hard for algorithms to detect without knowing the context at hand. Consider the following Twitter conversation where sentiment analysis failed.
Ambiguity in words: It is difficult to define the sentiment associated with words that are devoid of context.
For e.g.
- A slew of sanctions has been enacted against the offenders.
- They have got official sanctions to conduct this play.
In the first sentence, ‘sanction’ is used in a negative sense, whereas in the second it’s used in a positive sense.
Large documents: In addition to the challenges described above, large pieces of text are difficult to analyze due to the presence of multi-polarity sentences. Averaging polarity is a solution however it seldom produces good results.
A few recent developments in deep learning technology has helped alleviate these challenges in sentiment analysis ![]()
Word embeddings
Word embeddings are increasingly being used to solve various challenges in NLP. We wrote about Word Embeddings a little while ago. Several word embeddings such as Word2Vec, GloVe, and fasttext can be used for training and developing classification models.
The general idea behind word embeddings is to capture word semantics in a high dimensional vector. Algorithms such as shallow neural nets or dimensionality reduction over a large corpus of text like wiki pages, news articles, etc. create these embeddings.
Let’s take an example of how sentiment analysis uses pre-trained word embeddings such as Word2Vec. We will use the IMDB movie review dataset for our analysis. Word2Vec embeddings trained on Google News dataset with a vocabulary size of 3 million words are available for download here.
Python implementation
Word2Vec embeddings can be imported by using the gensim package as given below.
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300/GoogleNews-vectors-negative300.bin', binary=True)
Let’s load the reviews using pandas dataframe, do some pre-processing (such as removing special characters, lower casing etc.) and tokenize them in to words.
Pre-processing and tokenization
import pandas as pd
df = pd.read_csv("labeledTrainData.tsv", sep = "\t", error_bad_lines=False)
from bs4 import BeautifulSoup
import re
def get_tokens(reviews):
token_list = []
for line in reviews:
text = BeautifulSoup(line, "lxml").get_text()
sent = re.sub("[^a-zA-Z]"," ", text)
token_list.append(sent.lower().split())
return token_list
tokenized_reviews=get_tokens(df['review'])
Once we have tokenized reviews, we can create feature vectors for each review. Here we look up the word embedding of each word present in a review . Since, the semantics of each word in Word2Vec are expressed as a vector of length 300 features, we get a feature vector of size 300 dimension in performing the Word2Vec look-up. An average of all word embeddings in a review is obtained to get the feature vector of the entire review.
Document feature conversion
import numpy as np
def create_feature_vector(words, model, index2word_set, nwords):
featureVec = np.zeros(nwords, dtype="float32")
for word in words:
if word in index2word_set:
featureVec = np.add(featureVec,model[word])
featureVec=np.divide(featureVec,nwords)
return featureVec
def make_vectors(reviews, model, dim):
nreviews=len(reviews)
index2word_set=set(model.index2word)
feature_vec=np.zeros((nreviews, dim), dtype="float32")
counter=0
for review in reviews:
feature_vec[counter]=create_feature_vector(review, model, index2word_set, dim)
counter=counter+1
return feature_vec
vector_dimension=300
train_vectors = make_vectors(tokenized_reviews, model, vector_dimension)
Once our reviews are converted into feature vectors, let’s split our data into two sets – training and validation. Finally, we train a classification model on these features to obtain a Sentiment Analyzer.
Y = df["sentiment"]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_vectors, Y,
test_size = 0.2, random_state = 13, stratify = Y)
from sklearn.linear_model import LogisticRegression
logistic_regr = LogisticRegression()
logistic_regr.fit(X_train, y_train)
predict = logistic_regr.predict(X_test)
print(logistic_regr.score(X_train, y_train))
print(logistic_regr.score(X_test, y_test))
Transfer Learning
The above approach of using Pre-trained word embeddings is a simple case of Transfer Learning in analyzing Sentiments. Word embeddings are generated on a large corpus of text. A much smaller and different dataset uses the resultant weights.
However, this is still a small step when compared with transfer learning applications in Computer Vision/Image Recognition problems. Weights of pre-trained Neural Networks such as ResNet are used to create new Neural Networks. These networks are then tuned for several other Image recognition problems. This pre-tuning saves time and the required computation to train a Neural Network from scratch. On the other hand, we are only using pre-trained embeddings to generate features of the documents. When used as input to a Neural Net, the network still has to be trained from scratch.
This begs the question – Is it possible to use something like ResNet for text?
NLP’s ImageNet moment
Universal Language Model Fine-tuning (ULMFiT), is a transfer learning approach developed by fastai’s Jermy Howard & Sebastian Ruder. Here is a summary of this approach:
- A Language model neural network is trained on a large corpus of English dataset. This network can predict the next word by looking at previous context of words in a document.
- To predict the next word efficiently, this Neural Net must be smart enough to understand language semantics.
- The same network is then trained/tuned gradually by unfreezing Neural Network layers, on the classification dataset (e.g movies dataset).
- We now have a network that understands user movie review semantics. Perhaps we can use its knowledge for other tasks such as classification.
- Hence, using the weights obtained from the Language Model NN with a classifier at the top creates a new Neural Network. This then transfers the weights of the previous network to this new network.
Let’s see how we can implement this. We would be using fastai v1 library and free GPU provided by Google Collaboratory.
Python implementation
Import fastai classes and load the data (there is no need to install fastai v1 package if you are using collab)
from fastai.text import *
path = untar_data(URLs.IMDB)
path.ls()
Out[2]:
[PosixPath('/root/.fastai/data/imdb/tmp_lm'),
PosixPath('/root/.fastai/data/imdb/unsup'),
PosixPath('/root/.fastai/data/imdb/train'),
PosixPath('/root/.fastai/data/imdb/tmp_clas'),
PosixPath('/root/.fastai/data/imdb/imdb.vocab'),
PosixPath('/root/.fastai/data/imdb/README'),
PosixPath('/root/.fastai/data/imdb/test')]
Fastai v1 provides easy to use data_block API to perform actions such as pre-processing, splitting data into train, validation & test set, creating data batches etc.
As stated above the first step in this approach is creating a Language Model Network which can predict the next word by looking at the context of previous words.
We will be fitting the IMDB movie dataset on a Neural Net already trained on a large Wikipedia dataset. This pre-trained network already understands general English semantics and it would now learn how people write movie reviews.
The following code reads text data from files, tokenizes and then numericalizes it. It automatically creates labels (in our case, the next occurring word) and creates a databunch object encapsulating the training and validation data loader.
We will use the Neural Net trained on Wikipedia 103 dataset and tune it to our dataset of movie reviews.
Generate training and test set from input data for language modeling
bs=48
data_lm = (TextList.from_folder(path)
#Inputs: all the text files in path
.filter_by_folder(include=['train', 'test', 'unsup'])
#We may have other temp folders that contain text files so we only keep what's in train and
test
.random_split_by_pct(0.1)
#We randomly split and keep 10% (10,000 reviews) for validation
.label_for_lm()
#We want to do a language model so we label accordingly
.databunch(bs=bs))
learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.3)
We use fastai’s learning rate finder method to get the optimal learning rate for training the network with movie reviews. By looking at the plot, pick the learning rate value.
This value is just before the LR value that yields the lowest loss value. In our case this would be 1e-2.
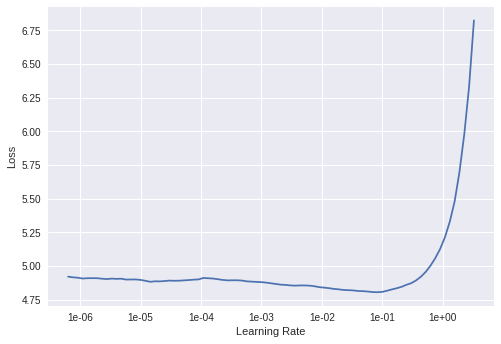
learn.lr_find() learn.recorder.plot() learn.fit_one_cycle(1, 1e-2, moms=(0.8,0.7))
Total time: 1:29:54 It takes around 90 minutes to run a single epoch on collab. Due to time constraints, we ran a single epoch. With powerful GPUs one can run multiple epochs for better results. The original fastai notebook executed 10 epochs.
What are fit_one_cycle & moms?
The fit_one_cycle method tunes the model by varying the learning rate in a cycle. In the first half of the cycle, the learning rate increases gradually reaching the maximum value. In the second half, the learning rate reduces to 1/10th or 1/100th the maximum value.
The assumption is that in the first half, the learning rate is initially low as the model is learning and does not have any knowledge. It slowly increases to the maximum value. This gradual rise prevents the model overshooting the local minima in the middle of training and prevents overfitting. As we train more epochs, the model is already learning a lot about the data. Therefore towards the end of the cycle the learning rate reduces drastically. This helps in finding the sweet spot of minima.
MOMS are the momentum value. How does momentum help? In Stochastic Gradient Descent (SGD) algorithm, the weights of a network update after each iteration. The last time step with the gradient subtracts from the weights times the learning rate.
Momentum helps in faster convergence of a model. The idea is to update the weights by taking a larger weightage of the weight update from the last iteration. This helps the model in reaching local minima with less number of iterations.
Let’s now see how the Network performs on language modeling tasks. We will generate a sequence of text by providing a few input words.
Text generation
TEXT = "it was the worse movie i"
N_WORDS = 40
N_SENTENCES = 2
print("\n".join(learn.predict(TEXT, N_WORDS, temperature=0.75) for _ in range(N_SENTENCES)))
it was the worse movie i 've ever seen ! it was so bad it was so bad , i remembered that my parents was so totally disgusted by the stupid scene where someone ( Steve Martin ) visits the nice guy and they
it was the worse movie i have ever seen . you do n't know how to say this movie was awful and i was really shocked at the poor acting . i have to say that this movie made me think that the movie should be
Even when trained on a single epoch the network produces sentences of reasonable quality. Let’s save the model encoder part which contains the hidden state.
learn.save_encoder('fine_tuned_enc')
Now, let’s create the Neural Net which can perform classification using the encoder part of the previous Language Model Network. However, before that, we create a new databunch object, this time with the Sentiment class labels.
Generate training and test set from input data for classification
path = untar_data(URLs.IMDB)
data_clas = (TextList.from_folder(path, vocab=data_lm.vocab)
#grab all the text files in path
.split_by_folder(valid='test')
#split by train and valid folder (that only keeps 'train' and 'test' so no need to filter)
.label_from_folder(classes=['neg', 'pos'])
#label them all with their folders
.databunch(bs=bs))
You can view the data of a single batch using:
data_clas.show_batch()
Create a Neural Network with the same encoder as the Language Model Network and load the pre-trained encoder:
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5)
learn.load_encoder('fine_tuned_enc')
Tune the last layers of the network and then gradually unfreeze and train the complete network:
learn.fit_one_cycle(1, 2e-2, moms=(0.8,0.7))
Total time: 11:46
learn.freeze_to(-2) learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))
Completed time: 13:25
learn.freeze_to(-3) learn.fit_one_cycle(1, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))
Total time: 20:22
learn.unfreeze() learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))
This is ~94% accurate on the validation set – a 7% improvement on using just word vectors.
Conclusion
The ULMFiT technique provides a robust way of using transfer learning in NLP problems and is a more prudent approach than using just Word Embeddings ![]()
This technique is effective even with scarcely labeled data. The language model network trained on a large corpus forms the bulk of language semantics. It is language-agnostic and hence can be used for other languages as well, as long as a large text corpus is available for training, which is not hard to obtain.
`With the success of ULMfiT, there are ongoing efforts at fast.ai to create Language Models for other languages as well.
Further reading
- fast.ai Jupyter notebook taken as reference for running the code can be found here.
- The 1cycle policy – https://sgugger.github.io/the-1cycle-policy.html
- Finding a good learning rate – https://sgugger.github.io/how-do-you-find-a-good-learning-rate.html

