Introduction
A machine learning pipeline is the materialization of applying MLOps techniques, tools, and processes to the machine learning lifecycle (see figure 1). Its main objective is to standardize and streamline the machine learning lifecycle. Additionally, it helps to improve communication and coordination among the number of experts needed to manage an ML project. This helps to reduce the friction, the risks, the hand-off between teams, the time to market, and increase the value flow from the idea to the production.
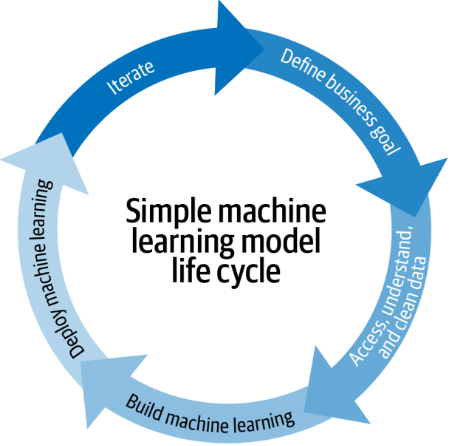
Figure 1: Machine Learning lifecycle
At the same time, this helps scale the ML development process to coordinate several projects simultaneously.
One way to tame this complexity is to create a machine learning pipeline.
ML pipeline
Traditionally, ML projects were approached from an individual, and relatively manual perspective, where a data science or machine learning expert trained a model and deployed it to production. However, as ML becomes critical to business strategy, more and more people and other systems become dependent on these solutions. It is at this point that ML solutions can become a bottleneck and cause friction in the value delivering flow because of the manual interventions, impossibility to reproduce models, complications in testing, difficulty in scaling, among other issues.
Therefore, it is necessary to apply the best software engineering practices to ML solutions. These practices include unit testing automation, continuous integration, continuous delivery, continuous deployment, infrastructure as code, etc.
A machine learning pipeline tries to orchestrate all tasks of the whole ML lifecycle process, from the business idea up to the deployment and maintenance. It encapsulates all the best practices for producing an ML model and allows the team to work and deploy at scale (Automation is preferred over manual -- which could lead to risky and error-prone tasks). An ML pipeline helps to increase team performance, reduce time to market, promotes experimentation, automates repetitive and complex tasks, and reduces value flow friction. There’s no one-size-fits-all solution when we talk about ML pipelines, but there are several common steps or phases in every ML project (as summarized in figure 2).
 Figure 2: a typical ML pipeline
Figure 2: a typical ML pipeline
The ML pipeline supporting the ML life cycle usually has the following steps:
- Model development
- Deployment
- Monitoring
- Maintenance
- Governance
These phases and what they should include will be discussed in the following sections.
Model development
Everything starts with a clear business objective. It could be as simple as reducing the percentage of loan default or improve the video recommendations to customers to increase the time they invest in a platform. We must define key performance indicators (KPIs) for all requirements. These KPIs will help us compare all trained models to choose the best one, the one that will be deployed to production.
We need to be careful when choosing the right KPIs: e.g., some projects could require a model with a high level of interpretability, maybe because the model prediction needs to be explained by a stakeholder to other people. This restriction might rule out some types of models, like neural networks.
Up next, an exploratory data analysis needs to be performed. In this phase we collect all the data that could help to fulfill the KPIs (process that sounds simple but it’s not). This is one of the most important steps in the whole ML process, because after analyzing the data you can tell if there’s enough data, with the quality needed to solve the problem.
The following needs to be considered in every exploratory data analysis: how the data is stored, where the data is stored, how much data you have, how much noise the data has, how biased the data is, how and which data will be accessed and processed by all project members, data format, data security, data integrity, data anonymization, among others.
Every type of ML (supervised, unsupervised, reinforcement, etc.) requires that the data meets certain characteristics so this is an important factor that needs to be determined in the process. This investigation helps to estimate how much time, costs, and resources (hardware/software) the project will need. The exploratory data analysis helps to select the best metrics (accuracy, precision, etc.) that could reflect that the ML model fulfills the projects KPIs.
In summary, the exploratory data analysis helps to get high-quality data, find data patterns, and create hypotheses.
Feature engineering is a crucial step in model development where the raw data is transformed into the format expected by the model in the training process. The data needs to be cleansed, data noise must be reduced, discard redundant or useless features, process outliers, create derived features from existing ones, encode features when needed (one-hot encoding, dummy encoding, hash encoding, etc.) or we could even apply dimension reduction techniques. Most of the time, the feature engineering step can consume approximately 60% of the project's time.
In the training and evaluation phase, the output of the feature engineering step (training, validation, testing sets, among others) is used to train multiple ML models. Training, testing, fine-tuning hyperparameters, and comparing models’ performance is an iterative process. This phase is probably the one that consumes most of the computing power available to the project because of the huge amount of data that needs to be processed and calculations that need to be performed to the train models.
Keeping a record of all experiment results produced by the training phase is a complex task because, in addition to the code versioning, the models and the data set used to train them needs to be versioned too. This is known as reproducibility and it’s important to include it in any ML pipeline. Nothing is more annoying for an ML expert than not being able to reproduce their results due to a faulty versioning strategy.
After training all models, they are evaluated and compared using the metrics defined in the exploratory data analysis phase, and usually the best model is deployed into production.
Deployment to production
Once the best model is chosen because it fulfills the requirements, meets the KPIs and has the best performance, it is time to package it and submit it to production. Usually, ML models are deployed into production in two main ways:
- Model as a service: a REST API (or SDK) is exposed to respond to client requests in real-time. Cloud service providers use this model.
- Embedded: The ML model is packaged inside another application and no external client can directly access the model. A common example is a recommendation system in an e-commerce website.
Given there’s no set standard in the ML world, it’s complex to generalize what software and platforms will be required in a project. But it’s normal to use Python or R as a programming language, cloud computing services for storage and processing, and big data software to transform data.
The models could be exported to some portable format like ONNX, PFA, or PMML but they are not popular enough yet and all of them have tradeoffs. One principle to follow in the whole ML pipeline, and highly recommended in the deployment stage, is to automate everything: prefer automation over intensive and error-prone manual processes.
The deployment phase must include the following tasks:
- Prepare the model to run in production
- Guarantee all code, standards and documentation are met
- Make sure all governance requirements are fulfilled by the model
- Certify the quality of all software and data artifacts
- Perform load and stress testing
- Perform integration tests
- Be ready for a rollback in case any error is found in the deployment process
Monitoring
A machine learning model is trained using a dataset, and we assume that the dataset reflects the real world. Then we can start using the model to make predictions because it resemblances abstract real-world patterns.
The reality is that the world keeps changing after the model is deployed into production, so the model quality can quickly, and unexpectedly, degrade without any warning until the business is negatively impacted (model decay). A static model cannot detect new patterns and retraining is inevitable. That’s why monitoring at the data level is a crucial step in the machine learning lifecycle.
There are several ways to monitor the model performance. The ground of truth strategy contrasts predictions vs. reality and if they differ according to a certain threshold, a retraining process is required.
Another technique is based on input drift. Let’s assume our model in production was trained with dataset X. After some time, the reality changes, and we have a new dataset Y. Is a retraining process required? To answer this question, we could use the next heuristic: if the data distribution (mean, feature correlations, standard deviation) diverges between datasets X and Y, then we have a strong indicator that the datasets could be different (the reality changed) so a retraining process must be considered.
A machine learning model must be monitored at the resource level as well, that is how much RAM, GPU, CPU, storage, network, disk, and other computing resources it consumes. To monitor the resource level of machine learning traditional DevOps tools and techniques can be used.
Maintenance
Developing and deploying improved ML models (retraining) is essential in the project lifecycle. There could be several reasons to retrain a model like performance degradation, bug fixes, changes in legislation, potential unintended bias introduced in the model, new KPIs, and introduction of new features.
No matter what, sooner or later, retraining must be done.
Before retraining, we need to know that some models are more stable than others. For example, a model predicting stock price is more unstable than an image classifier, so the former will require more retraining rounds. The cost of retraining versus the performance improvement must be considered too. Retraining is limited by the possibility to collect new quality data.
There must exist mitigation and contingency plans for unexpected situations, for example, we need to know what to do if after retraining the model with new data the performance is unacceptable.
Even after training a model, it cannot be “blindly” deployed to production. We need to compare the current model against the new one before deploying it. One common technique is shadow testing: when a client’s request is received, the current model serves it and returns a response, at the same time the request is sent to the new model. Both responses are recorded to be statistically analyzed later. The new model will be deployed if its performance is found to be better aligned to the current conditions/business needs.
Another option is to use A/B testing, where one request is served by one or other model, but not both. Then the results are analyzed to decide if we should keep the current model in production or deploy the new one.
Governance
Data governance concerns include, but it is not limited, ways to determine and manage the source of the data, provisions to make sure the data is accurate and up-to-date, protection of any type of sensitive personal information, determining how and under which terms was the data collected, among others.
Data is the heart of machine learning. Data cleaning, combination, transformation, transport, sharing, and anonymization is performed through the whole ML lifecycle. Data lineage is extremely important for ML to comply with national and international regulations like GDPR.
It’s easy to make a mistake and train models with bias that could discriminate or negatively impact the rights of several groups of people. Although making predictions based on data is a powerful tool, the results could be illegal or counterintuitive. For example, let’s assume that gender is one of the features in our datasets and we use it to train a model to predict if a bank must loan money: If for some reason women’s loans defaulted more than men, the model will discriminate for gender reasons, something completely illegal. In this scenario, we must remove gender from the ML datasets. The same applies to other potentially discriminatory features like ethnicity, age, health conditions, religion, and others.
Not only is data quality important, but process quality is also key for ML to succeed, and this is the objective of process governance. Process governance is the documentation, standardization, and audit of all steps and tasks performed in the ML lifecycle. The objective is to guarantee to carry out all activities in the right way at the right moment. For example, no ML model must be deployed to production until all validation and testing is finished. Another example would be to confirm that no ML model is trained with potential discriminatory features.
The idea is to enable surveillance of the ML pipeline for the risk analysts, project managers, legal specialists, and any other stakeholders to audit the whole process. The process of governance faces several challenges. Everybody must accept it and follow it through to be effective.
Additionally, if the process is heavyweight then people will try to find shortcuts or avoid it altogether, increasing the risk and the possibility to deploy low-quality models to production.
Another problem is that formal processes are hard to define without ambiguity, it’s highly unlikely that just one person in the team knows the whole process from beginning to end to be able to document it in a clear way.
Conclusion
The ML lifecycle is complex, there’s no question about it. ML projects require a systematic and efficient approach to building them. MLOps tools, processes, and best practices can be applied to create an ML pipeline. The ML pipeline is a way to automate, standardize processes, tame complexity, reduce time to market, promote continuous experimentation, support scalability, reduce risks, increase value flow from idea to production and reduce the feedback loop. The ML pipeline is not just tooling; it’s a way to reuse the company’s expertise and lessons learned from past ML projects. Teams that attempt to deploy machine learning models without a pipeline will face issues with model quality or worse, they could deploy models that have a negative impact on the business and/or customer satisfaction.

