Over the years, there has been a steady increase in demand for getting real-time or near real-time data for data analytics. In such scenarios, it becomes essential to determine how quickly the data can be made available in Snowflake post-generation.
There are several ways in which data available on external stages can be loaded into Snowflake using popular ETL tools like Informatica Cloud, Matillion, etc. But Snowflake also provides its own functionality to load the data from external stages into its tables. Snowpipe is Snowflake’s continuous data ingestion service, which enables loading data from files as soon as they are available in a stage.
What is Snowpipe?
Snowpipe is an ingestion pipeline, an out-of-the-box component, ready to use when you purchase Snowflake Datawarehouse. Snowpipe lends itself well to real-time data requirements, as it loads data based on triggers and can manage vast and continuous loading.
It is a “COPY INTO” command continuously looking for fresh files to process them in micro-batches as soon as they arrive at the staging area. Snowpipe eliminates the requirement to build near-real-time pipelines to process data from external locations.
A few key points to note about Snowflake Snowpipe.
- Snowpipe combines a filename and a file checksum to ensure only “new” data is processed.
- Snowpipe uses serverless architecture and Snowflake-supplied compute resources, and you are billed accordingly.
- Snowpipe loads data in response to new file notification events. These notification events are usually configured in cloud platforms.
- We can also trigger a Snowpipe manually from Snowflake or through custom programs calling the REST APIs.
Implementation of Snowpipe in Snowflake
Snowpipe is an automated service that continuously listens for new data as it arrives in Amazon Web Services (S3) cloud storage; it loads that data into Snowflake. At a high level, the first option is to point a Snowpipe to a bucket in AWS S3. Then, you define event notifications on your S3 bucket and send these event notifications to Snowflake. As soon as new files land in the S3 bucket, those files are automatically picked up by Snowpipe and loaded into your target table.
Initially, you place the file in the S3 bucket, and as soon as the file is placed, an S3 notification is set up. This S3 notification is sent to an SQS Queue provided by Snowpipe. After receiving the notification, the load from the file to the target database begins.
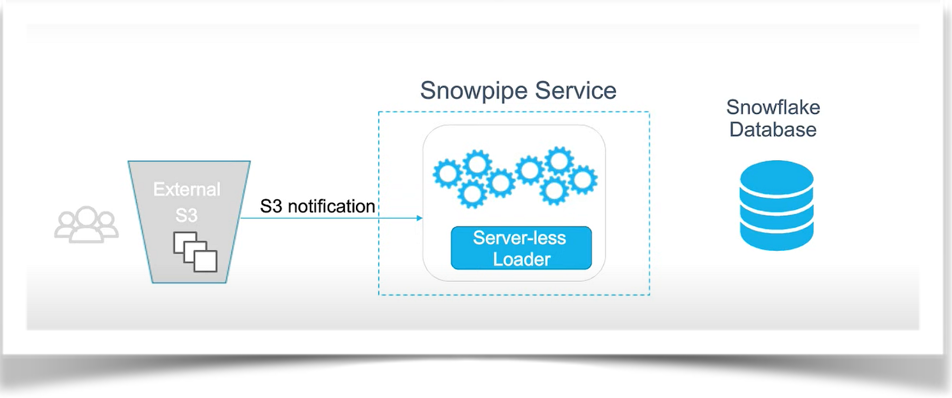
Fig: 1 Data Ingestion
Setting Up Snowpipe
- To create an External stage that points to the S3 bucket in Snowflake :
CREATE OR REPLACE STAGE SNOWPIPE_DEMO.PUBLIC.SNOW_STAGE URL = ‘s3://snowpipe-demo/’
- To define a target table for the Snowpipe to load data:
CREATE OR REPLACE TABLE SNOWPIPE.PUBLIC.SNOW_TABLE
- To create a pipe with the auto_ingest option equaling true, which indicates that we want to use the automatically configured SQS queue :
CREATE OR REPLACE PIPE SNOWPIPE.PUBLIC.SNOW_PIPE AUTO_INGEST=TRUE AS COPY INTO SNOWPIPE.PUBLIC.SNOW_TABLE FROM@SNOWPIPE_DEMO.PUBLIC.SNOW_STAGE FILE_FORMAT = ( TYPE= ‘JSON’);
- To look at the existing pipes:
SHOW PIPES;

Data Loading
Snowpipe has two main methods to trigger a data-loading process:
- Cloud Storage Event Notifications (AWS S3, GCP CS, Azure Blob)
Snowflake’s Snowpipe can be configured to load continuously into tables by enabling auto ingest and configuring the cloud provider event notification to initiate the data load. This method works only with the external stage. Different scenarios of data auto-ingestion using Snowpipe are listed below:
AWS S3 → SNS → SQS → Event Notification → Snowpipe → Snowflake table
Azure BLOB → Eventgrid → Event Notification → Snowpipe → Snowflake table
Google Bucket → PUB/SUB → Event Notification → Snowpipe → Snowflake table
- Snowpipe’s REST API
Snowflake also provides a REST API option to trigger Snowpipe data. This option is very useful if an on-demand data load is invoked or when there is a requirement to load data from an internal stage using Snowpipe. This can be called from any tool or programming language that supports REST calls.
The data loading is triggered when new data files land in AWS S3. The image below shows how both methods work:

Pricing
The utilization costs of Snowpipe include an overhead for managing files in the internal load queue. With more files queued for loading, this overhead will continue to increase. For every 1,000 files queued, you must pay 0.06 credits. For example, if your application loads 100,000 files into Snowflake daily, Snowpipe will charge you six credits.
Given the number of factors that can differentiate Snowpipe Streaming loads, it is challenging for Snowflake to provide sample costs. The size and number of records, data types, etc., can affect the computer resource consumption for file migration. Client charges are dictated by how many clients actively write data to Snowflake per second.
Account administrators (users with the ACCOUNT ADMIN role) or users with a role granted the MONITOR USAGE global privilege can use SQL commands to view the credits billed to their Snowflake account within a specified date range.
To query the history of data migrated into Snowflake tables, the amount of time spent loading data into Snowflake tables using Snowpipe Streaming, and the credits consumed, query the following views:
- SNOWPIPE_STREAMING_CLIENT_HISTORY View (in Account Usage).
- SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY View (in Account Usage).
- METERING_HISTORY View (in Account Usage).
Advantages of Snowpipe
- Real-time insights: It constantly offers fresh business data across all departments while avoiding workload issues.
- Reduces costs: It is cost-effective and charges customers per second based on computing time.
- Usability: It is simple to use. All you have to do is connect it to the S3 bucket, and the data will instantly load.
- Adaptable: It is highly adaptable and enables simple customization to load data using a programmatic REST API, Python, and Python SDKs.
- Zero Management: It scales up or down instantly. There is nothing that needs to be managed.
Summary
Snowpipe can load data from files as soon as the data is available in the stage. This means that instead of manually running scheduled COPY statements to load larger batches, you can load data from files in micro-batches, making data available to users in minutes. It is beneficial when external applications continuously land data in storage locations like S3 or Azure Blob. Snowpipe is a central element of Snowflake that provides businesses with new real-time perspectives to enable them to make data-driven decisions.
Acknowledgment
This piece was written by Talati Adit Anil from Encora.
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.

