In this blog, we are going to talk about GitOps, its patterns, pros, cons and challenges, including a brief example of how it integrates not only with Kubernetes but other declarative infrastructure tools.
Requirements
- Kubernetes cluster (Minikube or cloud provided)
- Fluxv2
- Git Repository
- Kustomize
- And IaaC tool such as ARM (Azure Resource Manager) or AWS CloudFormation
Introduction
GitOps applies the versioning and deployment process usually made for applications to infrastructural components, taking advantage of infrastructure as a code and the emerging tools, which allows us to have idempotent declarations of our infrastructure.
There are two ways to implement GitOps (Pull and push based), but they share one thing in common; setting a “source of truth”, that defines the characteristics of the infrastructure.
Multiple-Step Explanation
- Push based deployments
This might sound familiar. From the application point of view, we have source code and a pipeline which on its final step deploys the code using an agent. If using containers, in a push-based deployment, the new image is pushed to a registry., IaaC follows a similar process as outlined in the following diagram.:
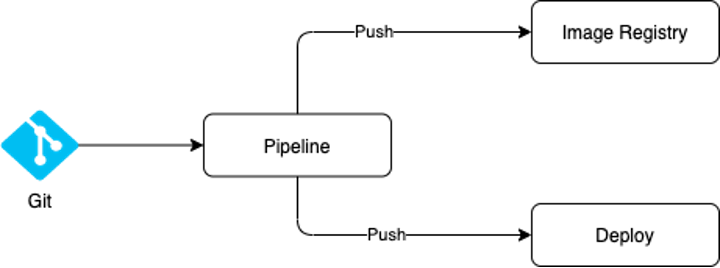
This approach allows us to have more control over the deployment process, as the pipeline manages the whole deployment, we can make use of all tools provided by the CI-CD agent of our choice, such as:
- Approvals and checks
- Variable replacement
- Secret injection
- Schedule deployments
Whilethe simplicity is very attractive it comes with a few downsides:
- It has a huge dependency on the pipeline for deployments, which means if the pipeline provider changes there must be a migration, as well if there is an error in the pipelines code, then deployments stop.
- Desynchronization: There is nothing that stops anyone with enough access to the cluster from making changes to the cluster or resources that differs from the source, thus making the “source of truth” less reliable
- The pipeline has an all-powerful access to apply different infrastructural changes. Sincethe more complex the infrastructure, the higher the permissions, it explains why most pipeline service principals end up with admin or write all permissions.
Once again, this is not wrong, and most pipelines would follow the above pattern.
- Pull based deployments
In this methodology, a new component, the operator, is introduced that constantly watches one or more sources of truth for changes and applies these changes when a difference is detected.
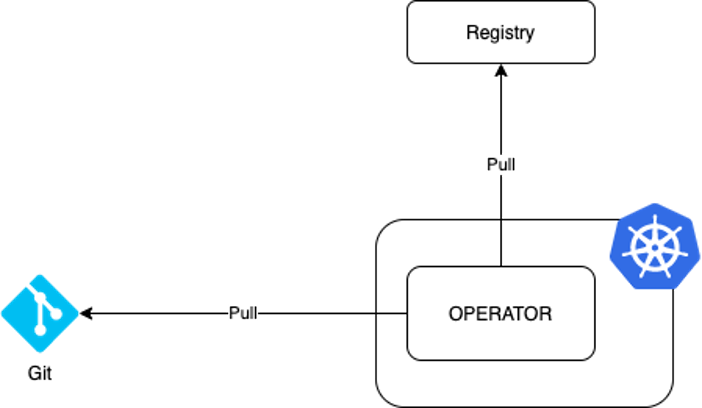
With this approach the operator takes over responsibility, and pull requests become more sensible as changes get reflected in the infrastructure as soon as it merges with the target branch. This methodology has some benefits:
- Changes gain immutability, which means any change made manually will me reverted or overwritten by the source of truth
- It works in both ways, thus allowing the operator to write to the source of truth
- RBAC is defined by the cluster, not the pipeline
- Multiple sources of trust can be leveraged such Git repositories, registries & Helm repositories.
However, this great automation process comes along with a few challenges:
- Increased complexity, depending on many factors which we will speak about later in this blog.
- Secrets management becomesa problem as secrets need to appear in the repository.
- Promotion and propagation of changes gets tied to the complexity of the repository structure
Examples
Let's take a quick example, in which I'll be using a local Minikube cluster, a GitHub repo and FluxV2.
First, we initialize the repository with the Flux components, for which you will need a PAT (Personal Access Token) from your git provider, in this case GitHub:
export GITHUB_TOKEN={PAT}flux bootstrap github \ --owner= {YOUR_USER} \ --repository= {YOUR_REPO} \ --path= {YOUR_FOLDER} \ --personal
We will see the following components created in our repo automatically, which represent the Flux system files
.├── flux-system│ ├── gotk-components.yaml│ ├── gotk-sync.yaml│ └── kustomization.yaml
Now we can add more folders alongside the Flux-system folder which would represent different namespaces and a sample application deployment (nothing too complex for this example).
Deployment.yamlapiVersion: apps/v1, kind: Deploymentmetadata: name: myapp namespace: demonpspec: replicas: 6 selector: matchLabels: app: myapp template: metadata: labels: app: myapp spec: containers: - name: myapp image: nginx:latest ports: - containerPort: 80
namespace.yamlapiVersion: v1kind: Namespace metadata: name: demonp
With the following directory structure
├── flux-system│ ├── gotk-components.yaml│ ├── gotk-sync.yaml│ └── kustomization.yaml├── demonp│ ├── deployment.yaml│ ├── namespace.yaml
And if we wait for a moment the declared resources will appear in the respective namespace.
NAME READY STATUS RESTARTS
myapp-6649684d9d-4zjcz 1/1 Running 0
myapp-6649684d9d-6s8kc 1/1 Running 0
myapp-6649684d9d-c54vj 1/1 Running 0
myapp-6649684d9d-htd2f 1/1 Running 0
myapp-6649684d9d-k8lz2 1/1 Running 0
myapp-6649684d9d-sz4qq 1/1 Running 0
Now comes the tricky section because you might ask the following questions:
- What if we need dev, staging and production environments?
- What if we have infrastructure spread over multiple repos?
- Should we start versioning secrets and sensible data?
- What if a team needs a copy of the environment?
- What if the infrastructure responsibility is divided into different teams?
- How do we manage promotions?
- How do we handle versioning?
For most of these questions the answer would depend on several factors.
From this point onwards, branch strategies, secrets management, repository management, responsibility management, promotion management, environment management and team organization become critical factors.
These factors help define how many clusters are required if there’sneed to separate environment per cluster or per namespace, The number of repositories that are needed, ability tohandle concurrent changes to the clusters, and change propagation through different environments.
Keep in mind that there isn't a “right way to do GitOps”, and that there are many paths which will accomplish the same goal, each with their corresponding pros and cons.
Let's analyze a few challenges:
A common branch strategy in which we have a dev and a main branch would usually need an environment for each branch. This means that we must have the ability to change configuration depending on the environment. In this case, all you need is to specify the branch to monitor
export GITHUB_TOKEN={PAT}flux bootstrap github \ --owner= {YOUR_USER} \ --repository= {YOUR_REPO} \ --path= {YOUR_FOLDER} \ --personal --branch= {YOUR_BRANCH}
This can also be achieved in the same branch by adding both environment files in the repository. We will though have to make some changes to our directory structure:
.CoreRepo└── deploy ├── base │ └── demo │ ├── deployment.yaml │ ├── kustomization.yaml │ └── namespace.yaml ├── dev │ └── demo │ ├── dev-patch.yaml │ └── kustomization.yaml └── prod └── demo ├── kustomization.yaml └── prod-patch.yaml└── cluster ├── dev │ ├── flux-system │ │ ├── gotk-components.yaml │ │ ├── gotk-sync.yaml │ │ └── kustomization.yaml └── prod ├── flux-system │ ├── gotk-components.yaml │ ├── gotk-sync.yaml │ └── kustomization.yaml
The Kustomization object has different values or patches depending on the environment. This implementation is known as “the monolith”, which is perfect for small projects but as more projects are added, it gets harder to navigate through the repository.
Another factor to keep in mind is “teams”. With time, as more projects and teams emerge, it gets overwhelming for a single person to handle this. Organizations add more people to infrastructure management, ideally one per team to separate the infrastructural components from the core components and different teams' components, which in turn means more repositories.


Kustomize and Helm may be used to add controllers to handle the complexity as more repositories are created.:
flux create source git source-demo \--url={YOUR_REPO} \--branch={YOUR_REPO} \--interval=40s \--export > ./cluster/dev/sources/source-demo-infra.yamlflux create kustomization git kustom-demo-infra \--source=source-demo-infra \--path=./deploy/dev/demo \--prune=true \--interval=30s \--export > ./cluster/dev/kustomizations/kustom-demo-infra.yaml
NOTE: this source was made using a public Git repo, if you have a private an organizational Git repo, then more flags and a ssh secret are needed to prevent authentication error.
flux create secret git app-demo-secret \--url= {YOUR_NEW_SOURCE_SSH_URL}kubectl get secret app-demo-secret -n flux-system -o json \| jq -r '.data."identity.pub"' | base64 –d
Then, add that ssh key decoded data into the Git repository as a deploy key and finally add this flag to the source:
flux create source git source-demo \--url={YOUR_REPO} \--branch={YOUR_REPO} \--interval=40s \--secret-ref app-demo-secret \--export > ./cluster/dev/sources/source-demo-infra.yaml
These files declare a new source which is in a different repository and how that source needs to be interpreted. Let's look at the new repository strategy:
RepoAppDemo└── deploy ├── base │ └── demo │ ├── deployment.yaml │ ├── kustomization.yaml │ └── namespace.yaml ├── dev │ └── demo │ ├── dev-patch.yaml │ └── kustomization.yaml └── prod └── demo ├── kustomization.yaml └── prod-patch.yaml
RepoCore└── cluster ├── dev │ ├── flux-system │ │ ├── gotk-components.yaml │ │ ├── gotk-sync.yaml │ │ └── kustomization.yaml │ ├── sources │ │ ├── source-demo-infra.yaml │ ├── kustomizations │ │ ├── kustom-demo-infra.yaml └── prod ├── flux-system │ ├── gotk-components.yaml │ ├── gotk-sync.yaml │ └── kustomization.yaml │ ├── sources │ │ ├── source-demo-infra.yaml │ ├── kustomizations │ │ ├── kustom-demo-infra.yaml
Now, there are more sources of truth managed by different people, but what about responsibility? What if the branching strategy is different? Some organizations only make PR (pull request) directly to main and handle release branches, so there’s need to listen to multiple branches.
Once again, there is no one right way to do GitOps, and it depends on the organizational needs.
What about DATA?
One of the problem areas is secrets management. Versioning connection string, keys and certificates doesn’t sound right, but there are two options.
- Versioning the secrets in the repository
 Encrypt in the repository and let a Kubernetes controller handle de-encryption on the cluster. In the repository, secrets exist as a hash.
Encrypt in the repository and let a Kubernetes controller handle de-encryption on the cluster. In the repository, secrets exist as a hash.- Use a cloud-provided secret manager to only declare the name or id of the secret in the yaml file and let the cloud provider handle the data. A good example would be csi driver.
- Don’t version anything at all and manage it manually. But this will add more manual steps in the deployment which might fail if you forget to create the secrets before converging the new changes into the repository.
So, is GitOps tied to Kubernetes?
Not exactly, though most pull-based tools for GitOps were designed with Kubernetes in mind. GitOps covers both pull and push based methods, but if we reconstruct the workflow without the Kubernetes related components, we can still make use of GitOps in either push or pull strategy with an IaaC tool that follows idempotency, like AWS CloudFormation, Azure Bicep or Terraform. In the pull case, there isn't a Flux-like tool and one needs to be created. This is not too hard. Let's analyze the following diagram:

Here, we would have an application “Source Controller” which would be constantly pinging the repositories for changes and apply the files if the latest commit changes. This can be a virtual machine, a serverless function or even a container running in your cluster as long as the files follow idempotency to ensure that changes would be additive rather than destructive.
In Python, an example would be like the following:
import subprocess
import re
import time
commit=''
repo_url = '{YOUR_REPO}'
def getCommit(repo_url):
proc=subprocess.Popen(["git","ls-remote",repo_url,stdout=subprocess.PIPE)
stdout, stderr = proc.communicate()
commit = re.split(r'\t+', stdout.decode('ascii'))[0]
return commit
def applyFiles():
#code to apply depending on your tool
return
def main():
old_commit=''
new_commit=''
while(True):
time.sleep(10)
new_commit=getCommit(repo_url)
if(new_commit!=old_commit):
applyFiles()
old_commit=new_commit
if __name__ == "__main__":
main()
Key Takeaways
- GitOps allows us to replicate the deployment automation for infrastructure as a code.
- There isn't one correct way to implement., The choice of method and complexity will depend on your organization, team, application requirements and strategies.
- Even though current GitOps tools were designed with Kubernetes in mind, this doesn't mean we can't apply the same concepts for other kinds of infrastructural deployments
Join Us at Encora
Are you a developer or engineer looking to make an impact on the world through technology? Visit Encora careers to join a passionate community of innovators and receive unmatched opportunities for professional development and benefits.
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.


