
Introduction
Site reliability engineering (SRE) and DevOps are two trending disciplines with quite a bit of overlap; their essential goals are understanding how to measure success or failure and how to gain continuous reliability across every application.Reliability is not just about the infrastructure, but is relevant every step of the way, from application quality to performance and security. Site Reliability Engineers care about every process from source code to deployment; that’s how they earn the reputation of being a true bridge from development to operations.
History:
While Site Reliability Engineers (SREs) work between development and operations, they don’t necessarily operate within DevOps . The concept of SRE has been around since 2003, which means that it precedes DevOps.The term was made popular by Ben Treynor, who created Google’s Site Reliability Team. According to Treynor, SRE is “what happens when a software engineer is tasked with what used to be called operations.”
What is SRE?
Site Reliability Engineering is an engineering discipline devoted to helping an organization sustainably achieve the appropriate level of reliability in its systems, services, and productions.SRE Core Principles
- SRE Focuses on reliability
- SRE Lives in the production
- SRE Manages scale and complexity
- SRE requires engineering and architecture
- SRE uses tech and respects people
SRE Practices
- Service level Indicators and service level objectives (SLIs and SLOs)
- Operational Balance
- Learning from Failure
How does an organization begin with SRE?
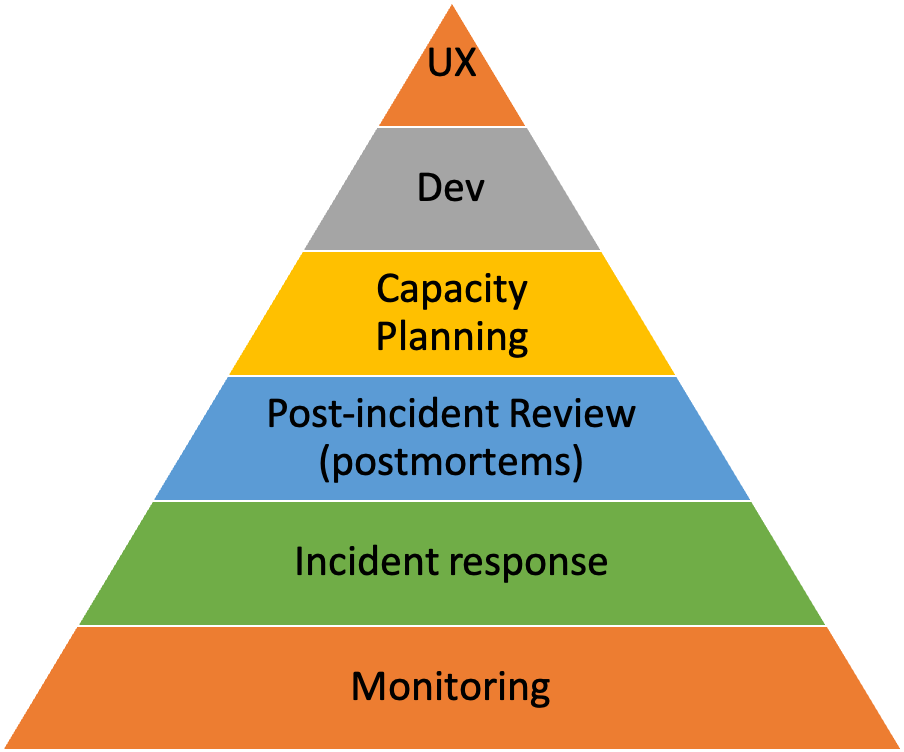
Mikey Dickerson’s Hierarchy of reliability
How Do You Start?
- Have a problem/ Downtime/epiphany
- Get management support lined up
- Read the available literature critically
- Spend time with other SREs
- Try out SLIs / SLOs
-
Site reliability engineers’ day to day work
Site reliability engineers measure service-level indicators (SLIs) and service level objectives (SLOs), while DevOps teams measure the failure rate plus the success rate over time. SREs share responsibilities related to the following DevOps pillars of infrastructural improvement.
-
Reduce organizational silos
Instead of discussing the number of existing silos in the company,SREs encourage everyone else to address the issue. This discussion is accomplished by using the tools and techniques across the company, helping spread ownership across all employees.
-
Accept failure as normal
-
Implement gradual change management
-
Leverage tooling and automation with smart dedications
-
Measure everything in the daily work
SRE teams need to know that everything is moving in the right direction. This can be accomplished by setting up alerts for various scenarios, embracing peer code review, and/or using unit tests.
Conclusion
Once you have a monitoring solution that meets your organization's needs — including complete coverage for your entire stack, unified views of hybrid environments, monitoring for ephemeral systems (containers/microservices), real-time models of your IT services, and massive scalability, you're then set up for success. Now you can take integrated data and insights from monitoring into incident response, root-cause analysis, remediation procedures, capacity planning, and so on at any scale.
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. As you evaluate IT monitoring solutions and their capabilities, check out how Encora can set your organization up to achieve the ultimate service reliability.

